Here’s my promise.
By the time you finish reading this, you’ll understand one of the most underappreciated (and budget-destroying) problems in modern AEO/GEO strategy… you have a finite number of prompts you can track, an infinite (and growing) universe of prompts your audience is actually using, and most tools don’t give you a framework for bridging that gap.
This is the problem of the universal prompt proxy. And getting it right is arguably more important than any content optimization tactic you’ll run this year.
Let’s start with the actual problem (and why nobody talks about it)…
If you’ve adopted an AEO or GEO monitoring tool in the last 12 months — Profound, Otterly AI, Peec AI, Scrunch, or any of the dozen others now fighting for your budget — you’ve already hit the wall. You get a plan. You get a prompt limit. And then you stare at a blank prompt library wondering: which ones do I actually track?
Otterly AI’s Lite plan gives you 15 prompts. Profound’s Starter tier gives you 50. Peec AI’s entry plan offers 25. Scrunch’s starter begins at 350 — but across 7 platforms, that’s effectively 50 unique questions. The per-prompt-per-platform math eats your budget fast.
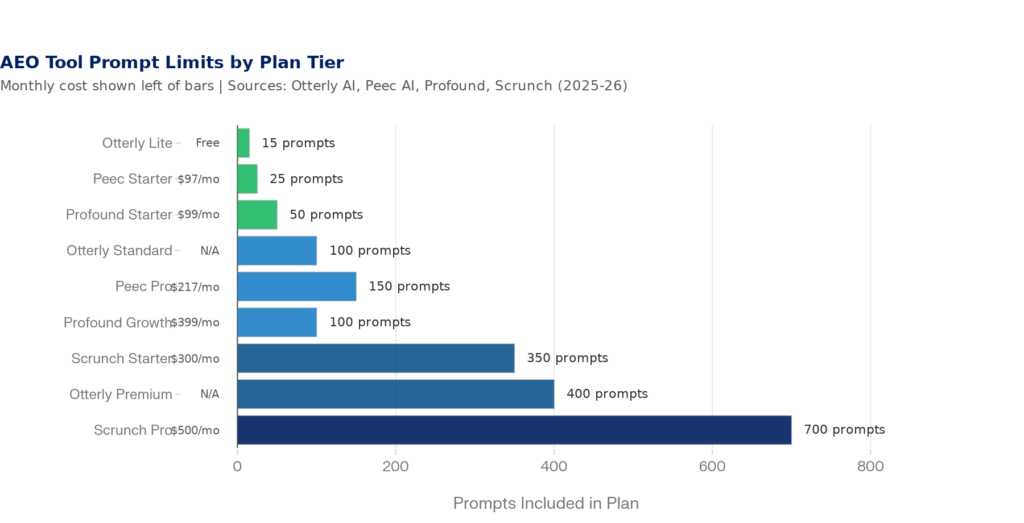
Figure 1: AEO Tool Prompt Caps by Plan Tier — most entry plans offer 15–100 prompts | Sources: Otterly AI, Peec AI, Profound, Scrunch pricing pages (2025–2026)
Meanwhile, your website exists in a world where over 70% of all search queries are long-tail — meaning highly specific, low-volume, and almost impossible to predict in advance. Google confirmed in 2025 that 15% of all daily searches are completely new queries it has never seen before. At 13.7+ billion daily searches, that’s over 2 billion brand-new queries every single day.
“15% of all queries Google sees are new every day. I would have thought at some point most searches would have been made — people just ask the same thing over and over again. But when we recalculate these metrics, it’s always around 15%.” — John Mueller, Google, Search Central Live NYC, 2025
Now layer on top of that the AI search revolution. ChatGPT alone processes 2.5 billion prompts per day — more than doubling from 1 billion just eight months prior. The average ChatGPT prompt is 60 characters long: roughly 17 times longer than the average Google search query (3.4 characters). These aren’t keywords. They’re conversations.
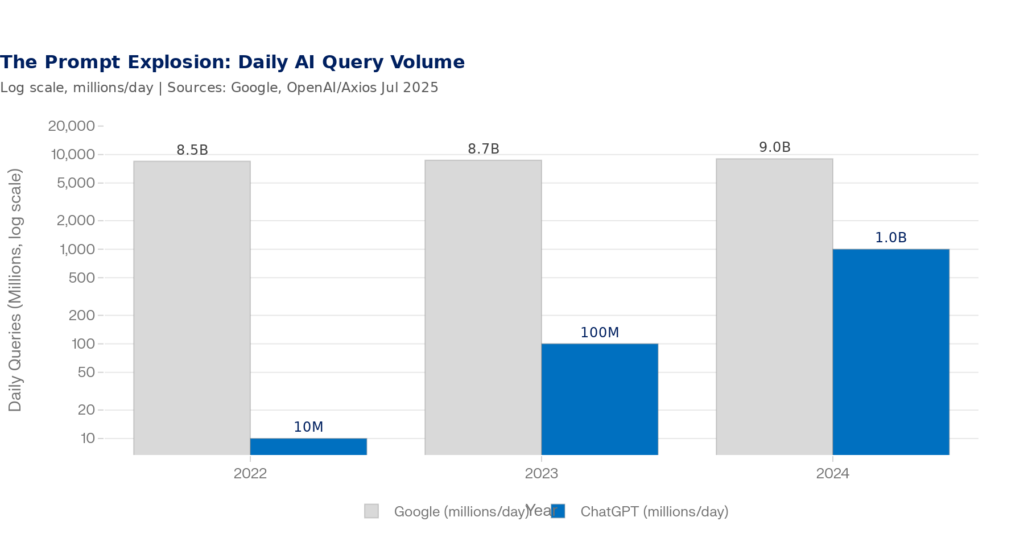
Figure 2: Daily AI Query Volume vs. Google — ChatGPT crossed 2.5B daily prompts in mid-2025 | Sources: OpenAI/Axios (Jul 2025), Google Year in Search 2025, SQ Magazine (2026)
Conversational AI has also driven a 70% surge in ‘Tell me about…’ style queries on Google year-over-year, and ‘How do I…’ searches hit all-time highs with 25% growth. The query universe isn’t just growing — it’s exploding in length, nuance, and variability.
So here’s the core tension you’re now living in: you have maybe 1000–5000 prompt slots in your AEO tool, and your audience could be asking hundreds of thousands of variations of questions about your category right now. Which 1-5k do you pick? And how do you know they’re actually representative of the whole universe?
Your AEO metrics — mention rate, citation share, sentiment — are only as good as the prompts you’re tracking. A misrepresentative prompt set gives you metrics that look meaningful but tell you almost nothing real about your actual AI visibility.
Why This Is Harder Than Keyword Research Ever Was
At least in traditional SEO, a keyword was a keyword. Everyone searching ‘best project management software’ got roughly the same search results page. The query was universal. That made it trackable, benchmarkable, and manageable.
AI prompts don’t work that way. Two people can ask the exact same question and receive completely different answers — because AI engines factor in the user’s history, platform context, location, prior conversation, and stated constraints. A founder at a 10-person startup asking ‘what’s the best CRM for my team?’ gets a different recommendation than a VP of Sales at a 2,000-person enterprise asking the same words.
On top of that, AI systems don’t actually search for the prompt you type. They use a process called query fanout where your original question gets decomposed into 4–20 parallel sub-queries that each pull separate content. Google AI Mode generates 8–12 sub-queries for standard queries and can spin up hundreds for Deep Search. ChatGPT averages 2.17 searches per prompt. Gemini fires off 8–10. Each of those sub-queries is a potential citation opportunity, and most brands aren’t thinking about them.
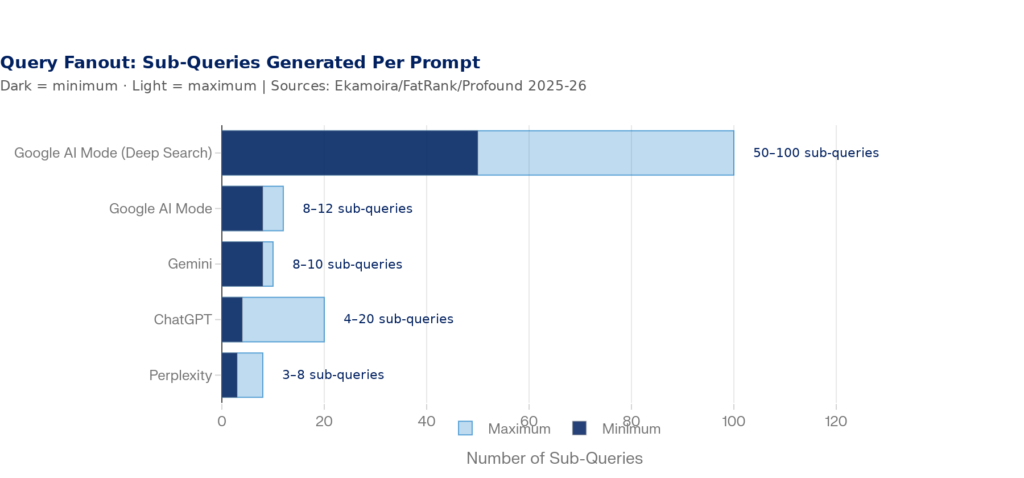
Figure 3: Query Fanout — Sub-Queries Generated Per User Prompt by AI Platform | Sources: Ekamoira Research (Feb 2026), FatRank (Feb 2026), Profound/Nectiv (2025)
What this means practically is that your 1k-5k prompt monitoring set isn’t really tracking 1k-5k questions. It’s tracking the surface-level triggers for potentially 10k–100k underlying sub-query evaluations. If your proxy set doesn’t represent your real query universe, the data you get back is noise masquerading as signal.
And the long tail makes this worse. Research consistently shows that 92% of all keywords receive 10 or fewer monthly searches. But these thin-volume queries collectively represent the majority of all search activity, and they’re precisely where AI prompt behavior concentrates. Someone asking ChatGPT isn’t typing ‘CRM software.’ They’re asking, ‘What’s the best CRM for a healthcare startup with 15 salespeople that integrates with Epic?’ That specificity is the long tail on steroids.
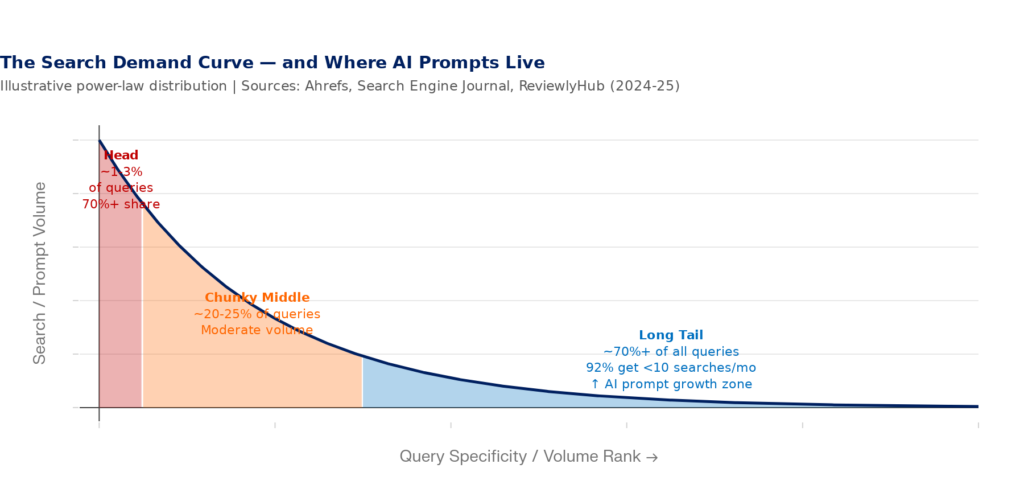
Figure 4: The Search Demand Curve — AI Prompts Accelerate Long-Tail Query Growth | Sources: Ahrefs, ReviewlyHub (2024–2025); demand curve is illustrative based on reported distributions
Why AI Visibility Matters More Than Traffic Share Suggests
As of April 2026, all AI chatbots combined (ChatGPT, Gemini, Claude, and Perplexity) account for only about 0.27% of global search referral traffic, according to Cloudflare Radar data.
The reason is conversion quality. AI-referred traffic converts at 14.2% — roughly five times the 2.8% rate of Google organic traffic, according to AI Labs Audit data from 2025. When an AI engine recommends your brand, the user has already gone through a filtering, comparison, and synthesis process that a traditional SERP never completes for them. They arrive pre-sold. AI platforms generated 1.13 billion referral visits in June 2025 (a +357% year-over-year increase). This channel is small, fast-growing, and disproportionately valuable.
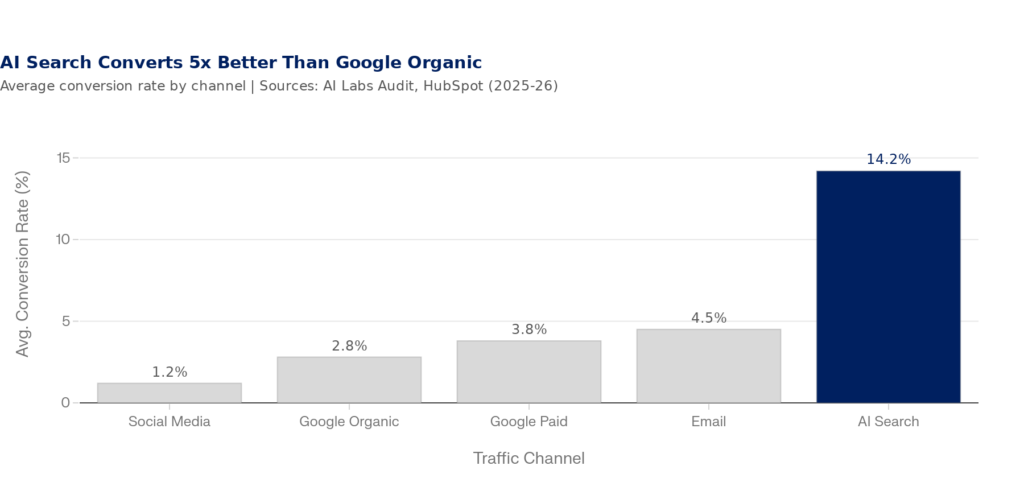
Figure 5: AI Search Converts at 14.2% — 5x Higher Than Google Organic | Sources: AI Labs Audit (2025), HubSpot Blog (2026)
The implication: a misrepresentative prompt proxy doesn’t just produce bad reporting. It actively misleads your content and strategy decisions for the highest-converting inbound channel you now have. If your 1k-5k prompts are all top-of-funnel brand awareness queries, you’ll think you’re winning in AI search while your bottom-of-funnel consideration and decision prompts (where buyers actually convert) are completely dark.
Introducing the Universal Prompt Proxy
A universal prompt proxy is the smallest set of carefully selected, representative prompts that collectively reflect the full diversity of how your audience actually queries AI systems about your category, product, and brand.
It’s not about tracking every possible prompt — that’s wild sauce. It’s about sampling the query space strategically, the same way a pollster doesn’t survey every voter to predict an election with reasonable accuracy. The goal is statistical representativeness, not exhaustive coverage.
What is a Prompt Proxy? Your prompt proxy is like a well-constructed scientific sample: it doesn’t need to include every possible query — it needs to include the right distribution of query types, intentions, personas, and funnel positions so that trends in your sample reflect trends in the full universe.
Most current AEO practice treats prompt selection as a ‘get it done and move on’ task. The Overthink Group, which has written extensively on prompt architecture, describes it bluntly: ‘if you don’t set up your sample prompts strategically, you’ll waste a lot of time and a lot of money to get a lot of noise.’ Their research recommendation is 7–10 prompts per topical report to achieve statistically meaningful sentiment readings. HubSpot’s AEO coverage recommends 50–100 prompts per product line for multi-model reliability. The gap between what tools give you and what you need to be meaningful is very real. My take? Aim for 250-500 prompts per category if your credits allow, and make sure you’re covering for both the user journey and various search intent evenly with each set.
The 5 Dimensions of a Representative Prompt Set
But before you go off any start making changes in your AEO tool, you need to understand the five dimensions your prompt set must cover. Think of these as the axes of your sampling space. A good proxy set has intentional representation across all five.
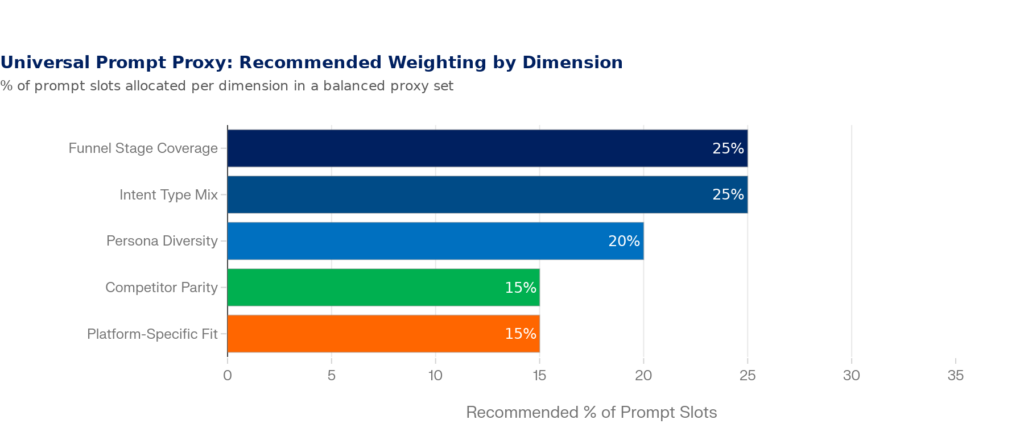
Figure 6: The 5 Dimensions of a Universal Prompt Proxy — Recommended Slot Allocation | Framework developed from Lumenuse, Overthink Group, Modern Marketing Partners, and Overthinkgroup.com AEO architecture research (2025–2026)
| Dimension | What It Covers | Example Prompts |
| 1. Funnel Stage (25%) | Awareness, Consideration, Decision — each stage produces different query structures and different brands mentioned by AI | “What is [category]?” / “Best [product] for [use case]?” / “Is [Brand] worth it?” |
| 2. Intent Type (25%) | Informational, Navigational, Transactional, Comparison — AI engines respond very differently to each | “How does X work?” / “X vs Y for Z” / “Where to buy X” / “X pricing” |
| 3. Persona Diversity (20%) | Different buyer roles, company sizes, and constraints produce different AI recommendations — same product, different prompts | “Best CRM for solo consultant” vs “Best enterprise CRM for 500+ users” |
| 4. Competitor Parity (15%) | Competitive prompts reveal how AI frames your category and whether your brand appears in comparison contexts | “Alternatives to [Competitor]?” / “Pros and cons of [Competitor]” |
| 5. Platform-Specific Fit (15%) | ChatGPT, Google AI Overviews, and Perplexity behave differently — prompts should be platform-native, not crop-dusted | Short keyword phrases for AI Overviews; conversational full-sentence prompts for ChatGPT |
Table 1: The Five Dimensions of a Universal Prompt Proxy | The 7-Step Process for Building Your Proxy Set
Here’s the actual workflow from blank slate to a finished, defensible prompt library that you can load into your AEO tool with confidence. Lumenuse recommends starting with 100–200 candidate prompts before cutting down. This process gives you that raw material systematically.
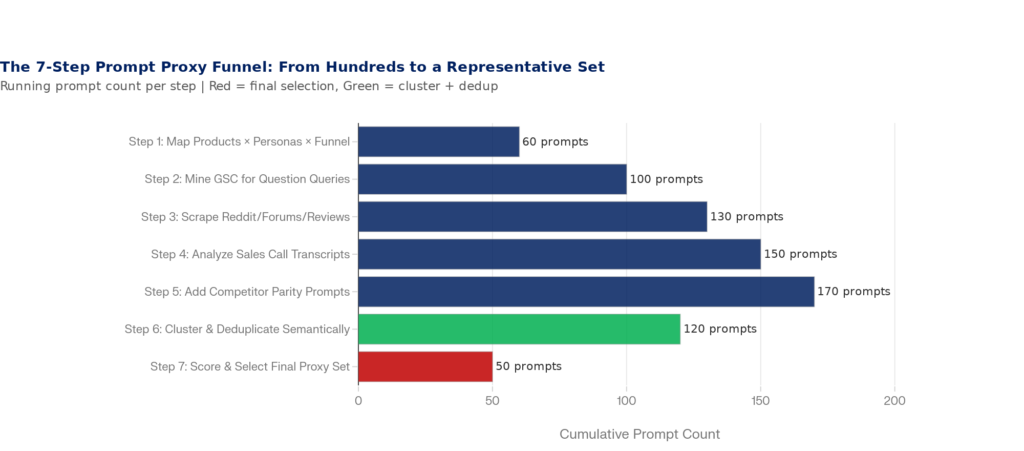
Figure 7: The 7-Step Prompt Proxy Funnel — From Discovery to a Representative Final Set | Framework synthesized from Lumenuse (Feb 2026), Overthink Group (Jan 2026), Modern Marketing Partners (Feb 2026)
Step 1: Build the Product × Persona × Funnel Matrix
Start top-down. Take every product or service you offer, every meaningful buyer persona, and every funnel stage (Awareness, Consideration, Decision). At each intersection, write 3–5 prompts that persona would realistically ask an AI engine at that stage. A founder in awareness mode asks completely different things than a procurement manager at decision stage, even when the product is the same.
For a B2B SaaS company with 2 products, 3 personas, and 3 funnel stages, this matrix alone produces 54–90 candidate prompts before you’ve mined a single external source. Keep all of them for now.
Step 2: Mine Google Search Console for Question Queries
Your GSC performance report is sitting on thousands of questions your existing audience actually asks. Filter for queries starting with ‘how,’ ‘what,’ ‘which,’ ‘best,’ and ‘should I.’ These question-shaped patterns align directly with how AI engines decompose prompts into sub-queries during fanout. Every long-tail GSC query is a candidate for your proxy set — and these have the advantage of being grounded in real, demonstrated user intent on your existing audience.
Step 3: Scrape Reddit, Forums, and Review Sites
Reddit and Quora hold the raw, unpolished questions real buyers ask before a purchase — phrased in exactly the natural language they use when talking to ChatGPT. Search your category keywords on Reddit and read the threads. Notice how people frame things: the specific constraints, the head-to-head comparisons, the edge cases. G2, Capterra, and Trustpilot review titles are also goldmines — ‘I switched from X to Y because…’ is a buyer consideration prompt in disguise. Add these verbatim to your candidate list.
Step 4: Analyze Sales Call Transcripts
Your sales reps hear the same questions over and over: ‘How does this integrate with HubSpot?’ ‘How does your pricing stack up against [Competitor]?’ These are prompts, not just objections. The same questions that arise on discovery calls are being asked to ChatGPT by buyers who never contact your team. Pull your last 20 call recordings, flag recurring questions, and — critically — note how the prospect phrases it, not how your rep answers it. That buyer phrasing is your prompt language.
Step 5: Add Competitor Parity Prompts
For every branded or category prompt about you, add the equivalent prompt for your top 2–3 competitors. This isn’t vanity — it’s methodology. Without competitive parity in your prompt set, you can’t distinguish your brand’s AI positioning problems from category-wide patterns. If AI says your pricing is a con, is that a you problem or does it say the same thing about every SaaS tool in your space? Competitive prompts answer that question.
Step 6: Cluster and Deduplicate Semantically
By now you likely have 120–200 candidate prompts. Many are semantically equivalent — asking the same underlying question with different phrasing. This is where you apply semantic clustering rather than just keyword matching. Tools like Ahrefs, Semrush keyword clustering, or even a simple vector embedding comparison (SBERT, OpenAI embeddings) will group prompts by meaning, not surface words. If two prompts land in the same semantic cluster, keep only the most natural-sounding, representative phrasing.
Pure TF-IDF keyword matching will fail here — it groups by shared words, not shared meaning. A prompt asking ‘What software helps manage customer relationships?’ and ‘Best CRM for small business?’ share almost no words but belong in the same semantic cluster. Use embedding-based similarity for this step.
Step 7: Score and Select Your Final Proxy Set
With your deduplicated list down to 60–80 candidates, apply a simple priority scoring model. Score each prompt across four dimensions: business impact (does this topic drive revenue for you?), prompt volume (how many people are actually asking this?), competitive relevance (do competitors show up strongly here?), and actionability (can you actually create content or earn citations for this prompt?).
Select prompts that achieve the highest scores across all four dimensions while maintaining balanced representation across your five proxy dimensions (funnel, intent, persona, competitor parity, and platform fit). Your final set should have a minimum of 7–10 prompts per topical report area and at least 50–100 prompts across your total tracked set for statistically meaningful trend data.
| Prompt Example | Business Impact | Volume Signal | Competitor Relevance | Priority Score |
| “Best [category] for [ICP use case]?” | ★★★★★ | ★★★★☆ | ★★★★★ | HIGH |
| “What is [Category]?” | ★★☆☆☆ | ★★★★★ | ★★★☆☆ | MEDIUM |
| “[Brand] vs [Competitor]” | ★★★★★ | ★★★☆☆ | ★★★★★ | HIGH |
| “How to solve [Pain Point]?” | ★★★★☆ | ★★★★☆ | ★★★☆☆ | HIGH |
| “Pros and cons of [Category]” | ★★★☆☆ | ★★★☆☆ | ★★★★☆ | MEDIUM |
Table 2: Example Prompt Priority Scoring Matrix — Score on impact, volume, and competitive relevance to prioritize your final proxy set
Real-World Sizing: How Many Prompts Do You Actually Need?
Let’s get specific about numbers. The ‘right’ number of prompts depends on the complexity of your product landscape and how many distinct buyer journeys you need to cover. But here’s a practical sizing framework based on current tool capabilities and measurement reliability thresholds:
| Business Type | Recommended Total Prompts | Per Topical Report | Starting Budget Tier |
| SMB / Single Product | 30–50 total | 7–10 per report | Otterly Standard or Profound Starter |
| Mid-Market / 2–3 Products | 75–150 total | 10–15 per report | Profound Growth or Scrunch Starter |
| Enterprise / Multi-Product | 200–400+ total | 15–25 per report | Otterly Premium or Scrunch Pro |
| Agency / Multi-Client | 400+ pooled | Varies by client | Enterprise custom pricing |
Table 3: Prompt Set Sizing by Business Type — based on statistical reliability thresholds from Rankscale, HubSpot, and Overthink Group (2025–2026)
One important caveat on tool math: some platforms count per-platform tracking separately. Scrunch’s 350-prompt Starter plan tracks each prompt on a single platform — if you want one question tracked across 7 platforms, that costs 7 prompt slots. So your effective unique prompt budget may be 5–7x smaller than the headline number suggests. Always calculate your real unique-question budget before designing your proxy set.
The per-platform prompt multiplication problem is one of the most misunderstood budget traps in AEO tooling. 50 prompts tracked across 5 platforms = 10 unique questions being monitored. Design your proxy set accordingly.
The Platform-Specific Problem: One Proxy Set Doesn’t Rule Them All
One of the most common proxy set mistakes is using the same prompts across every AI platform. This feels efficient. It’s actually a measurement error.
Google AI Overviews users are still searching — their queries are closer to traditional keyword searches, just longer. ChatGPT users are having conversations — they write full, contextual, multi-constraint prompts averaging 60 characters. Perplexity users tend to ask research-oriented questions with an expectation of citations. Gemini users in Google Workspace context may ask work-task oriented questions completely different from B2C scenarios.
| Platform | Typical Prompt Style | Avg Query Length | Best Proxy Format |
| Google AI Overviews | Keyword-adjacent, slightly expanded | ~10 chars (6x shorter than ChatGPT) | “Best [category] for [use case]” |
| ChatGPT | Conversational, multi-constraint, contextual | ~60 chars (17x longer than Google search) | “What’s the best way for a [persona] to [goal] with [constraint]?” |
| Perplexity | Research-oriented, comparison-seeking | Medium-length, citation-friendly | “Compare [A] vs [B] for [specific scenario] with sources” |
| Gemini | Task-oriented, workflow-integrated | Varies by context | “Help me [task] using [tool]” or “[Category] for [use case]” |
Table 4: Platform-Specific Prompt Formats for AEO Monitoring — Sources: SimilarWeb (Dec 2025), HasMeta (Feb 2026), Overthink Group (Jan 2026)
The practical implication: budget your platform-specific prompts deliberately. If you have 100 total prompt slots and monitor 4 platforms, you have roughly 25 unique questions per platform. Don’t try to track all 25 on all 4 platforms. Prioritize: use Google AI Overviews for top-of-funnel discovery prompts, ChatGPT for complex consideration and comparison prompts, and Perplexity for research and deep-dive prompts. Treat each platform as a different lens, not a duplicate audience.
Maintaining Your Proxy: It’s a Living Document, Not a Setup Task
Here’s the operational discipline most teams skip: your prompt proxy needs regular maintenance cycles, not just an initial setup. AI engine behavior shifts as models retrain, new competitors enter your category, and your audience’s language evolves. A prompt set that represented your audience perfectly in Q1 2025 may be meaningfully stale by Q1 2026.
There are also tracking continuity risks to manage carefully. When you change, add, or remove prompts in your AEO tool, it stops tracking the old prompts and begins fresh on the new ones. Your month-over-month trends break. You lose historical baselines. The Overthink Group warns explicitly: if you spend your first year tweaking your prompt set, you’ll never have a clean before-and-after view of your optimization efforts. This makes front-loading your proxy design — before you even subscribe to a tool — critically important.
| Cadence | Action | Trigger |
| Monthly | Review prompt-level performance; flag underperforming prompts | Routine reporting cycle |
| Quarterly | Audit proxy coverage against new products, competitor changes, seasonal shifts | Strategy planning cycles |
| Semi-Annually | Full semantic re-clustering of candidate pool; consider new platform additions | Model update announcements or major AI platform changes |
| Ad hoc | Add new prompts for new products, campaigns, or emerging competitor threats | Product launch, PR event, competitive entry |
Table 5: Prompt Proxy Maintenance Cadence — adapted from Lumenuse (Feb 2026) and Overthink Group (Jan 2026)
The Bigger Picture: Your Proxy as a Strategic Asset
At its best, a well-constructed universal prompt proxy isn’t just a tool configuration artifact — it’s a living strategic document that maps the language of your market. When you build it rigorously, it does three things most brands haven’t even started doing:
First, it gives you a defensible measurement baseline that tracks actual AI visibility trends rather than cherry-picked queries. When leadership asks why AI visibility is up or down, you can point to a structured, representative sample — not a convenience sample of queries someone thought sounded right.
Second, it becomes a content roadmap. Every prompt in your proxy set represents a content opportunity — a page, a structured answer, a schema-marked FAQ block — that can increase your probability of being cited when that prompt (or its semantic equivalents) fires through an AI engine. The Princeton GEO study found that adding expert quotes improved AI visibility by ~41%, statistics by ~30%, and inline citations by ~30%. Your proxy tells you exactly which topics to optimize first.
Third, it creates cross-team alignment. When sales, content, SEO, and leadership all understand the same 25 prompts that represent your AI visibility landscape, you stop having the ‘I asked ChatGPT and it didn’t mention us’ conversation. Everyone is working from the same representative picture.
AI-referred traffic currently converts at 14.2% — five times the rate of Google organic. The brands that get their prompt proxy right in 2025–2026 are building durable competitive advantage in the highest-converting discovery channel that currently exists. The brands that guess at their prompts are flying blind.
Start Here: Your First 30 Days
If you’re starting from scratch or realizing your current prompt set needs a rebuild, here’s where to invest your first 30 days:
| Week | Action | Output |
| Week 1 | Build your Product × Persona × Funnel matrix; generate 60–90 candidate prompts | Initial candidate prompt spreadsheet |
| Week 2 | Mine GSC, Reddit, G2/Capterra reviews, and sales call transcripts for 40–60 more candidates | 100–150 total candidate prompts |
| Week 3 | Apply semantic clustering to deduplicate; add competitor parity prompts; score and prioritize | Final 50–100 proxy set with priority scores |
| Week 4 | Load into your AEO tool; establish baselines; set first quarterly review date | Live tracking dashboard + first baseline report |
Table 6: 30-Day Universal Prompt Proxy Build Plan
The investment is real — this takes meaningful time to do properly. But the alternative is spending $4,000+ per month on AEO monitoring tools that are faithfully reporting on a proxy set that doesn’t represent your actual audience. That’s not a data problem. That’s a strategy problem. And it starts with the prompts.
—
Research for this article sourced from: Otterly AI pricing documentation (Apr 2026), Profound pricing/blog (Mar 2026), Peec AI pricing (2026), Scrunch pricing (2026), Overthink Group AEO Prompt Architecture (Jan 2026), Lumenuse AEO Prompt Guide (Feb 2026), Modern Marketing Partners (Feb 2026), Google/John Mueller Search Central Live NYC (2025), OpenAI/Axios ChatGPT usage data (Jul 2025), SimilarWeb ChatGPT query length study (Dec 2025), AI Labs Audit conversion data (2025), Ekamoira query fanout research (Feb 2026), FatRank query fanout (Feb 2026), Princeton GEO Study (via Surmado, 2026), ReviewlyHub long-tail keyword study (Dec 2025), Ahrefs AI Overviews content study (Dec 2025), Google Year in Search 2025 (TechBuzz.ai, Apr 2026).









Leave a Reply